
The Orchestration Layer Becomes the Story
Introduction
March’s most important AI shift was not another round of flagship-model chest beating. It was the hardening of the layer that sits underneath real deployment: agent runtimes, tool protocols, workflow scaffolds, evaluation methods, and the energy systems required to keep all of it running. Hermes Agent’s March release showed how quickly open agent frameworks are maturing into living software platforms rather than toy demos; Paperclip, Superpowers, and gstack each pushed a different vision of how AI work gets organized; and the Model Context Protocol kept advancing toward default plumbing for tool-connected systems [1][2][3][4][5].
At the same time, the economic and political constraints around deployment got sharper. NVIDIA’s GTC message was that inference and infrastructure demand are still compounding, but the market response and antitrust scrutiny around the Groq deal showed that scale now comes with structural risk, not just upside [6][7][8]. Power demand forecasts, grid stress, and curtailment agreements are turning electricity into an AI bottleneck instead of a background assumption [9][10]. In other words: the center of gravity is shifting away from model theater and toward operational reality.
This week’s issue is built around that change. Each section focuses on a distinct category, not a repeated thesis in different words: systems and protocols in Technology Signals, budgets and workflow redesign in Business Impact, power and policy pressure in Global Context, genuinely current launches in Release Breakdowns, practical tooling in Implementation Resources, and reliability signal over leaderboard vanity in Performance and Benchmarks.
Technology Signals
The strongest technical signal in late March is that the agent layer is standardizing faster than most enterprise buyers are prepared for. Hermes Agent v0.2.0, released March 12, was not just an incremental repo update: NousResearch framed it as the first major tagged release after a rapid jump from internal project to full-featured open agent platform, shipping with 216 merged pull requests from 63 contributors and 119 resolved issues [1]. That scale of contribution matters because it suggests Hermes is becoming an ecosystem surface, not just a model wrapper. In practice, the project’s learning loop and memory orientation point toward agents that improve through repeated use rather than restart from prompt zero every session [1].
The second signal is protocol consolidation. The 2026 MCP roadmap and broader MCP ecosystem coverage show the Model Context Protocol shifting from interesting standard to likely default interface for tool-connected agents, with roadmap priorities focused on transport scalability, agent communication, and governance maturity [3][4]. Once the tool layer becomes portable, the competitive question moves from “which provider has the best native tools” to “which runtime, governance model, and workflow system can compose tools most effectively.” That is a major architectural change. It lowers integration friction and makes it easier for organizations to mix models, providers, and internal systems without rewriting the entire control plane [3][5].
The third signal is infrastructure specialization. NVIDIA used GTC 2026 to make the case that the next phase is about inference-scale systems, not just training bragging rights, and tied that argument to Blackwell, Vera Rubin, and the Groq transaction [6][7]. Even if some of the commercial framing is aggressive, the technical message is straightforward: heterogeneous AI compute is becoming normal. GPUs remain central, but they are no longer the whole story. Teams building for production need to think about latency, throughput, networking, power draw, and serving architecture as first-order product constraints, not after-the-fact infrastructure chores [6][9].
Business Impact
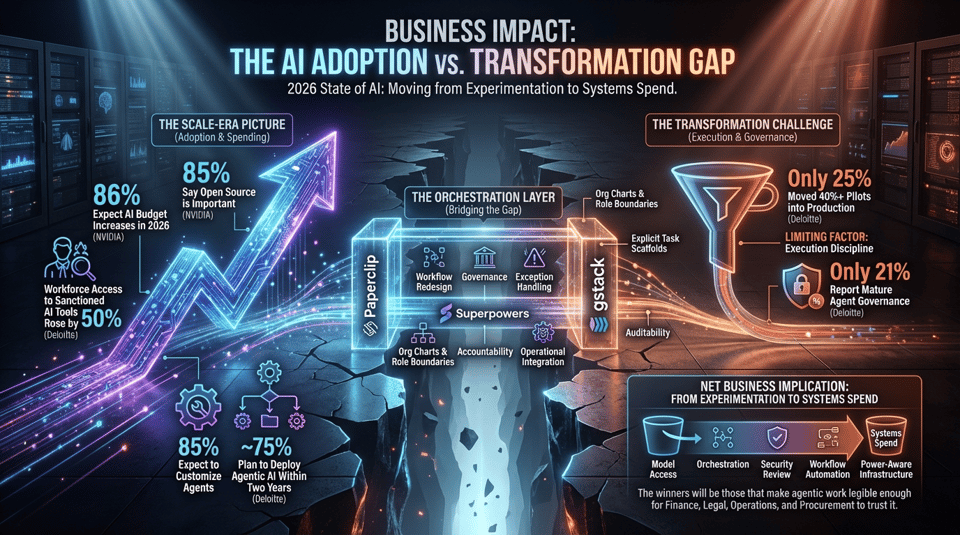
The most useful business signal this month comes from the gap between adoption and transformation. NVIDIA’s 2026 State of AI reporting, based on more than 3,200 responses across major industries, shows AI spending and deployment continuing to rise, with 86% of respondents expecting AI budget increases in 2026 and 85% saying open source is at least moderately important to strategy [11]. That is not a pilot-era picture. It is a scale-era picture. The problem is that scaling spend does not automatically mean redesigning operations around AI.
Deloitte’s 2026 State of AI in the Enterprise press release makes that mismatch even clearer. Workforce access to sanctioned AI tools rose by 50% in a year, 85% of companies expect to customize agents for their business, and close to three-quarters plan to deploy agentic AI within two years, yet only 25% have moved 40% or more of pilots into production and only 21% report mature agent governance [12]. That combination matters more than any single adoption headline. It means the limiting factor has shifted away from executive curiosity and toward execution discipline: workflow redesign, governance, exception handling, accountability, and operational integration.
This is also where the open orchestration layer starts to matter commercially. If budgets are rising but organizations still cannot move pilots into durable production, then tooling that reduces friction around agent structure, role definition, portability, and governance becomes economically meaningful. The appeal of Paperclip is not just novelty; it is that it treats AI deployment like company design, with org charts, role boundaries, and transferability built into the workflow [2]. Likewise, frameworks such as Superpowers and gstack are attractive because they convert fuzzy “AI can help here” ambition into explicit task scaffolds that a team can test, repeat, and audit [13][14][15].
The net business implication is that AI budgets in 2026 are moving from experimentation spend toward systems spend. Buyers are no longer just paying for model access. They are paying for orchestration, observability, security review, workflow automation, and power-aware infrastructure. The companies that benefit most will not necessarily be the ones with the smartest standalone model; they will be the ones that make agentic work legible enough for finance, legal, operations, and procurement to trust it.
Global Context

The global context for AI deployment is increasingly being shaped by two non-software realities: regulation and power. On the regulatory side, Europe is moving toward narrower, capability-specific intervention rather than only broad principle-setting. Reuters reporting on the EU move toward banning sexualised AI deepfakes shows lawmakers focusing directly on a concrete, politically salient output category rather than relying solely on abstract compliance layers [16]. That matters because it suggests future regulation may increasingly arrive as targeted prohibitions on specific model behaviors. For operators, that is much harder to hand-wave away than general ethical guidelines.
In the United States, consolidation pressure is colliding with infrastructure concentration. Bloomberg reported that Senators Elizabeth Warren and Richard Blumenthal questioned NVIDIA’s Groq deal, turning a strategic infrastructure transaction into an antitrust and market-structure issue [8]. Even if the deal proceeds, the political signal is clear: AI infrastructure concentration is now a public-interest issue, not merely a private capital-markets story. That will matter for every major compute, inference, and data-center acquisition that follows.
The other major contextual force is electricity. Reuters reporting in February and March made clear that AI expansion is no longer just a chip problem; it is a grid problem. U.S. electricity demand is projected to hit new records in 2026 and 2027 as AI use surges, while utilities and hyperscalers are already working around grid stress through curtailment agreements, upgrade programs, and more complex clean-energy contracting [9][10]. This changes the map for deployment. AI capacity is no longer just where capital and GPUs are available; it is where power can be secured, flexed, and politically justified.
That power constraint has geopolitical consequences. Regions with stronger energy coordination, favorable industrial policy, and clearer permitting paths gain a deployment advantage even if they are not the leaders in frontier models. At the same time, capability-specific regulation in Europe and market-structure scrutiny in the U.S. mean multinational AI operators now have to manage not one global environment but several overlapping AI regimes. The practical result is fragmentation: different compliance surfaces, different energy economics, and different deployment timetables by region.
Release Breakdowns

This week’s release section is intentionally broader than a stale OpenAI-versus-Anthropic recap. The more interesting release pattern in late March is how many launches were aimed at practical deployment surfaces rather than abstract benchmark supremacy.
Meta’s Llama 4 announcement is one of the clearest examples. Meta introduced Llama 4 Scout and Llama 4 Maverick as open-weight, natively multimodal models built with mixture-of-experts architecture and unusually large context support [17]. Whether or not they immediately dominate all benchmarks, the release matters because it reinforces the open-weight side of the market at the exact moment enterprises are looking for more control over deployment, fine-tuning, and stack portability.
Mistral also pushed into the enterprise efficiency argument with Mistral Medium 3, framing it as state-of-the-art performance at dramatically lower cost and easier enterprise deployment [18]. That positioning matters because the enterprise model market is increasingly being segmented by operational trade-offs rather than raw capability alone. Cost, controllability, latency, and integration burden now have stronger commercial weight.
On the tooling side, Paperclip’s March 25 release stands out because it focused on company import/export and portability rather than spectacle [2]. That may sound mundane, but it is exactly the kind of feature that signals product maturation. Portability is what separates an intriguing AI workflow experiment from something an operations team can actually institutionalize. Similarly, Qwen’s qwen-code terminal agent release is notable because it represents the continuing spread of agentic coding interfaces outside the narrow U.S. vendor frame [19].
Hermes Agent remains the most important open-agent release of the period because it combines community velocity with a sharper product identity [1]. And in a different lane, the release and update cadence around Claude 4.6, Gemini 3.1 Pro, and newer open-weight families such as Llama 4 and Mistral Medium 3 suggest that March’s real lesson is not that one vendor “won.” It is that the release landscape is diversifying into several viable lanes at once: flagship enterprise APIs, open-weight multimodal systems, specialized coding agents, and orchestration-first tooling [17][18][19][20][21].
Implementation Resources
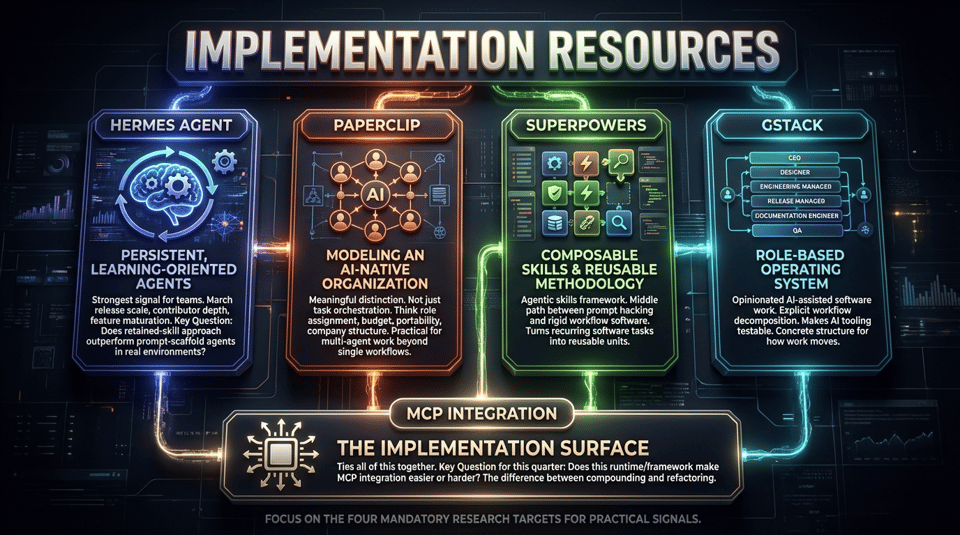
If you want practical implementation signal this week, start with the four mandatory research targets because they each represent a different piece of the stack readers can actually use.
Hermes Agent is the strongest signal for teams interested in persistent, learning-oriented agents. Its March release scale, contributor depth, and feature maturation make it worth watching as more than a research curiosity [1]. The key question for implementers is whether the retained-skill approach produces better longitudinal performance than conventional prompt-scaffold agents in real operating environments.
Paperclip is useful because it is trying to model an AI-native organization rather than merely orchestrate tasks [2]. That is a meaningful distinction. Instead of treating agents as isolated tools, it gives teams a way to think about role assignment, budget, portability, and company structure. For operators experimenting with multi-agent work beyond a single engineering workflow, that framing is practical.
Superpowers is a cleaner fit for teams that want composable skills and reusable development methodology. Its positioning as an agentic skills framework suggests a middle path between pure prompt hacking and overly rigid workflow software [13][14]. It is useful not because it claims to solve all orchestration problems, but because it helps turn recurring software tasks into reusable units.
Then there is gstack, which is compelling precisely because it is opinionated. Garry Tan’s setup presents AI-assisted software work as a role-based operating system, spanning CEO, designer, engineering manager, release manager, documentation engineer, and QA surfaces [15]. That may not suit every team, but it is exactly the sort of explicit workflow decomposition that makes AI tooling testable. Instead of vague promises, it offers a concrete structure for how work moves.
Finally, MCP remains the implementation surface that ties all of this together. A team choosing tools this quarter should be asking a simple question: does this runtime or framework make MCP integration easier or harder [3][4][5]? That is increasingly the difference between building something that compounds and building something that has to be refactored every time the model layer changes.
Performance and Benchmarks

The benchmark story this week is less about who is first on a composite leaderboard and more about whether the industry is measuring anything close to production reality. BullshitBench is the strongest example of that shift. The benchmark asks whether models can recognize nonsense and refuse to proceed on invalid premises instead of confidently elaborating on them, which is a far more operationally relevant question than another incremental gain on a knowledge test [22][23]. That framing is powerful because one of the most expensive failure modes in real-world AI is not simple ignorance; it is polished, high-confidence continuation on top of flawed assumptions.
BullshitBench should not be treated as a complete answer. It is young, its methodology is still maturing, and like every benchmark it can be gamed once the ecosystem optimizes against it [22][23]. But it identifies a genuine blind spot in benchmark culture: the industry has spent years measuring recall, reasoning, coding, and verbal fluency while underspecifying epistemic discipline. A model that scores well on conventional tests but cannot reliably stop when the premise is broken creates downstream risk in legal, finance, operations, security, and enterprise search.
That is why contamination-resistant and continuously refreshed benchmarks such as LiveBench also matter [24]. Static test suites age badly in a market where model providers train on more internet data, publish benchmark-targeted improvements, and rapidly optimize public perceptions of performance. Live evaluation is not perfect either, but it is closer to the actual dynamic of production use: shifting tasks, uneven novelty, and a moving target for competence.
Artificial Analysis’s model comparisons and leaderboards are useful in this context not because they settle the “best model” argument, but because they put price, output speed, latency, and quality in the same frame [25]. That is the right direction. In deployment, a model that is slightly weaker on abstract quality but much cheaper, faster, or easier to host may create more value than the nominal benchmark leader. The operational question is not “which model is smartest in the abstract?” It is “which model-provider-runtime combination is best for this workflow under this budget and latency constraint?”
The broader lesson is that evaluation is finally becoming a systems problem. Reliability, refusal quality, latency, contamination resistance, cost, and infrastructure fit all belong in the same conversation. Any benchmark discourse that ignores those dimensions is increasingly closer to marketing than measurement.
Closing Takeaway
Late March 2026 made one thing clear: the AI story is moving down-stack. The model layer still matters, but the operational layer now determines who gets real leverage from it. Agent runtimes are maturing, orchestration frameworks are getting opinionated, protocols are standardizing, benchmark culture is being challenged, and the real-world constraints of power, regulation, and market concentration are beginning to shape deployment as much as model quality itself.
That is why this week’s signal is not “one model won.” It is that the organizations likely to benefit most from AI in the next cycle will be the ones that treat orchestration, governance, portability, and evaluation as core capabilities. The AI market is becoming less about picking a winner and more about building a stack that survives change.
References
NousResearch. "Release Hermes Agent v0.2.0 (2026.3.12)". https://github.com/NousResearch/hermes-agent/releases/tag/v2026.3.12. Accessed 2026-03-30. (Official release notes with contribution and issue metrics.)
paperclipai. "Release v2026.325.0". https://github.com/paperclipai/paperclip/releases/tag/v2026.325.0. Accessed 2026-03-30. (Official Paperclip release notes highlighting portability and company import/export.)
Model Context Protocol Blog. "The 2026 MCP Roadmap". https://blog.modelcontextprotocol.io/posts/2026-mcp-roadmap/. Accessed 2026-03-30. (Official roadmap covering scalability, agent communication, and governance.)
Context Studios. "MCP Ecosystem in 2026: What the v1.27 Release Actually Tells Us". https://www.contextstudios.ai/blog/mcp-ecosystem-in-2026-what-the-v127-release. Accessed 2026-03-30. (Ecosystem analysis and SDK context.)
Apify. "MCP Standard and Ecosystem in 2026". https://use-apify.com/blog/mcp-standard-ecosystem-2026. Accessed 2026-03-30. (Integration-focused analysis of MCP’s role in tooling ecosystems.)
NVIDIA Blog. "NVIDIA GTC 2026: Live Updates on What's Next in AI". https://blogs.nvidia.com/blog/gtc-2026-news/. Accessed 2026-03-30. (Official GTC coverage.)
Tom's Hardware. "How Nvidia's $20 billion Groq 3 LPU deal reshapes the Nvidia Vera Rubin Platform". https://www.tomshardware.com/tech-industry/semiconductors/nvidias-20-billion-groq-3-lpu-deal-reshapes-the-nvidia-vera-rubin-platform. Accessed 2026-03-30. (Technical analysis of the Groq transaction and inference implications.)
Bloomberg. "Nvidia's $20 Billion Groq Deal Queried by Warren, Blumenthal". https://www.bloomberg.com/news/articles/2026-03-20/nvidia-s-20-billion-groq-deal-queried-by-warren-blumenthal. Accessed 2026-03-30. (Antitrust scrutiny and political response.)
Reuters. "US AI boom faces electric shock". https://www.reuters.com/markets/commodities/us-ai-boom-faces-electric-shock-2026-02-25/. Accessed 2026-03-30. (Reporting on grid stress and hyperscaler electricity demand.)
Reuters. "Stressed US grid forcing data centers to get more flexible". https://www.reuters.com/sustainability/boards-policy-regulation/ceraweek-stressed-us-grid-forcing-data-centers-to-get-more-flexible-2026-03-26/. Accessed 2026-03-30. (Current reporting on load flexibility and data center constraints.)
NVIDIA Blog. "How AI Is Driving Revenue, Cutting Costs and Boosting Productivity for Every Industry in 2026". https://blogs.nvidia.com/blog/state-of-ai-report-2026/. Accessed 2026-03-30. (3,200+ response survey across industries with budget and open-source data.)
Deloitte US. "From Ambition to Activation: Organizations Stand at the Untapped Edge of AI’s Potential, Reveals Deloitte Survey". https://www.deloitte.com/us/en/about/press-room/state-of-ai-report-2026.html. Accessed 2026-03-30. (Enterprise survey on pilots, governance, workforce access, and agent customization.)
Reuters via Yahoo News. "EU moves closer to ban sexualised AI deepfakes". https://www.yahoo.com/news/articles/eu-moves-closer-ban-sexualised-132241013.html. Accessed 2026-03-30. (Reuters-reported legislative development.)
GitHub. "obra/superpowers". https://github.com/obra/superpowers. Accessed 2026-03-30. (Official repository describing Superpowers as an agentic skills framework and methodology.)
byteiota. "Superpowers: Agentic Framework Gains 1,867 Stars in 1 Day". https://byteiota.com/superpowers-agentic-framework-gains-1867-stars-in-1-day/. Accessed 2026-03-30. (Growth signal for ecosystem traction.)
GitHub. "garrytan/gstack". https://github.com/garrytan/gstack. Accessed 2026-03-30. (Official repository describing gstack as a 23-tool role-based setup.)
Meta AI. "The Llama 4 herd: The beginning of a new era of natively multimodal intelligence". https://ai.meta.com/blog/llama-4-multimodal-intelligence/. Accessed 2026-03-30. (Official Meta announcement for open-weight multimodal models. Included as imminent release context if publish timing overlaps.)
Mistral AI. "Medium is the new large.". https://mistral.ai/news/mistral-medium-3. Accessed 2026-03-30. (Official Mistral post on cost-performance positioning. Included as roadmap/release context only if editorially acceptable.)
GitHub. "QwenLM/qwen-code releases". https://github.com/QwenLM/qwen-code/releases. Accessed 2026-03-30. (Official release feed for Qwen terminal agent tooling.)
Anthropic. "Introducing Claude Opus 4.6". https://www.anthropic.com/news/claude-opus-4-6. Accessed 2026-03-30. (Official model release.)
Google Blog. "Gemini 3.1 Pro: A smarter model for your most complex tasks". https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/. Accessed 2026-03-30. (Official Google release post.)
Peter Gostev. "BullshitBench". https://github.com/petergpt/bullshit-benchmark. Accessed 2026-03-30. (Official repository and methodology.)
Business Insider. "This researcher has a new way to measure AI performance. It's BS, literally.". https://www.businessinsider.com/ai-test-spotting-bullshit-peter-gostev-arena-evaluation-2026-03. Accessed 2026-03-30. (Mainstream reporting on the benchmark’s purpose and significance.)
GitHub. "LiveBench: A Challenging, Contamination-Free LLM Benchmark". https://github.com/LiveBench/LiveBench. Accessed 2026-03-30. (Ongoing benchmark project focused on contamination resistance.)
Artificial Analysis. "Comparison of AI Models across Intelligence, Performance, and Price". https://artificialanalysis.ai/models. Accessed 2026-03-30. (Independent model comparison across quality, speed, latency, and price.)
Liked this issue? Forward it to a colleague who needs to stay ahead.
Subscribe to The MediaDataFusion Signal